最近在学 ruby, 也用了 rspec, 传统的 xUnit 是 TDD 指导思想下的产物, 而 rspec 则算是 BDD (Behavior Driven Development) 影响下的产品。
TDD 和 BDD 区别究竟何在呢?
首先是思路上的区别, 传统的 TDD 关注的是接口是否被正确地实现了, 所以通常每个接口有一个对应的单元测试函数。而 BDD 通常以类为单位, 关注一个类是否实现了文档定义的行为。
具体从 rspec 的实现上来看, 主要有如下的不同
1. rspec 可以成为设计的一部分 , 你在设计一个类的时候, 一般会先写这个类需要实现哪些功能, 然后在逐个实现需求,
比如 XmlParser, 你会先计划他有三个特性, 支持从字符串初始化, 支持"=="符号, 支持序列化为字符串,
这时候你就可以写下如下的测试代码
# xml_parser_spec.rb
describe "XmlParser" do
it "should support init with string"
it "should support =="
it "should can convert to string"
end
此时运行如下的命令就可以看到你规划的类行为
$ spec -f n xml_parser_spec.rb
XmlParser
should support init with string (PENDING: Not Yet Implemented)
should support == (PENDING: Not Yet Implemented)
should can convert to string (PENDING: Not Yet Implemented)
...
上面的输出可以清晰地看到 XmlParser 需要支持的功能。你不用把这些功能需求记在脑子里, 也不放在你的 TODO 列表里,直接放这儿就行了
2. 使用一个句子来描述你要测试的行为, 而不是简单的重复被测试的接口名, 比如一个典型的测试:
it "should return [Miniblog] with different id" do
其中的 "should return [Miniblog] with different id" 就是这个测试的描述
3. 多级的 context, 便于将类的行为分到多个组, 同时每个组可以有不同的上下文环境(setUp+tearDown), 比如一个 xml parser, 如下所示的测试代码可以把行为分为两组,在遇到合法数据时的行为以及遇到非法数据时的行为
describe XmlParser do
context "with valid data" do
before do
@valid_data = "<a>123</a>"
end
...
end
context "with invalid data" do
before do
@invalid_data = "<a>123</b>"
end
...
end
end
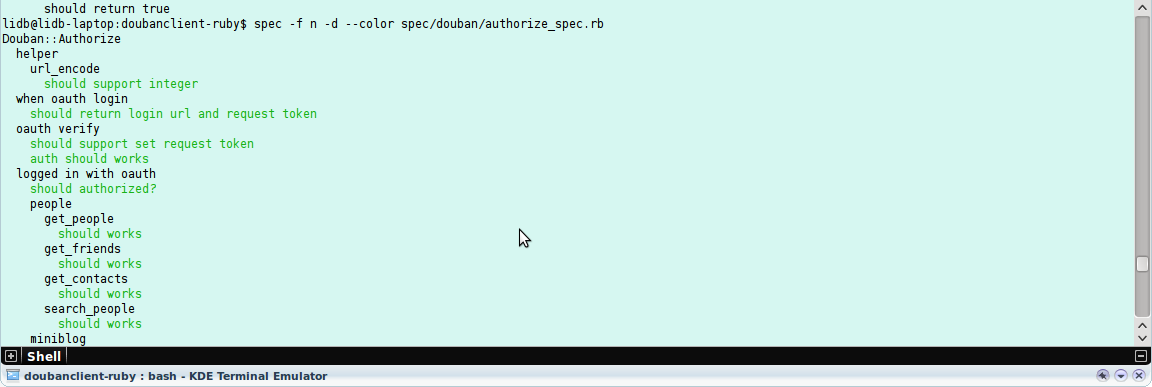
4. 支持自动文档化, 在1里已经可以看到 spec 支持生成一个简略的文档来描述你的对象, 下面是一个比较长的例子用于描述 Douban::Authorize 的功能, 树状的结构把类的功能分到了多个小组
5. 表述更接近自然语言的习惯, 比如 xUnit 通常使用 assertEqual(a, 1), 而 rspec 经常使用 a.should == 1
相对于 TDD 来说, 这些都不是什么革命性的突破。但是思路的转变,能够让你的开发更流畅。
首先你在设计时就可以开始写测试代码, 在开发完成后可以通过 rspec 生成的文档来快速浏览你是否完成了所有特性。这些性质都能让测试驱动开发更容易推广。从我的工作经验来看, 由于种种原因 (比如没有迭代周期, 缺乏 code review 制度, 没有硬指标的覆盖率要求...), 大家的测试代码写得很少。而在 rspec 的帮助下, 直接看 rspec 生成的文档就可以督促大家补全测试。
参考资料
[1] The RSpec Book
TDD 和 BDD 区别究竟何在呢?
首先是思路上的区别, 传统的 TDD 关注的是接口是否被正确地实现了, 所以通常每个接口有一个对应的单元测试函数。而 BDD 通常以类为单位, 关注一个类是否实现了文档定义的行为。
具体从 rspec 的实现上来看, 主要有如下的不同
1. rspec 可以成为设计的一部分 , 你在设计一个类的时候, 一般会先写这个类需要实现哪些功能, 然后在逐个实现需求,
比如 XmlParser, 你会先计划他有三个特性, 支持从字符串初始化, 支持"=="符号, 支持序列化为字符串,
这时候你就可以写下如下的测试代码
# xml_parser_spec.rb
describe "XmlParser" do
it "should support init with string"
it "should support =="
it "should can convert to string"
end
此时运行如下的命令就可以看到你规划的类行为
$ spec -f n xml_parser_spec.rb
XmlParser
should support init with string (PENDING: Not Yet Implemented)
should support == (PENDING: Not Yet Implemented)
should can convert to string (PENDING: Not Yet Implemented)
...
上面的输出可以清晰地看到 XmlParser 需要支持的功能。你不用把这些功能需求记在脑子里, 也不放在你的 TODO 列表里,直接放这儿就行了
2. 使用一个句子来描述你要测试的行为, 而不是简单的重复被测试的接口名, 比如一个典型的测试:
it "should return [Miniblog] with different id" do
其中的 "should return [Miniblog] with different id" 就是这个测试的描述
3. 多级的 context, 便于将类的行为分到多个组, 同时每个组可以有不同的上下文环境(setUp+tearDown), 比如一个 xml parser, 如下所示的测试代码可以把行为分为两组,在遇到合法数据时的行为以及遇到非法数据时的行为
describe XmlParser do
context "with valid data" do
before do
@valid_data = "<a>123</a>"
end
...
end
context "with invalid data" do
before do
@invalid_data = "<a>123</b>"
end
...
end
end
4. 支持自动文档化, 在1里已经可以看到 spec 支持生成一个简略的文档来描述你的对象, 下面是一个比较长的例子用于描述 Douban::Authorize 的功能, 树状的结构把类的功能分到了多个小组
5. 表述更接近自然语言的习惯, 比如 xUnit 通常使用 assertEqual(a, 1), 而 rspec 经常使用 a.should == 1
相对于 TDD 来说, 这些都不是什么革命性的突破。但是思路的转变,能够让你的开发更流畅。
首先你在设计时就可以开始写测试代码, 在开发完成后可以通过 rspec 生成的文档来快速浏览你是否完成了所有特性。这些性质都能让测试驱动开发更容易推广。从我的工作经验来看, 由于种种原因 (比如没有迭代周期, 缺乏 code review 制度, 没有硬指标的覆盖率要求...), 大家的测试代码写得很少。而在 rspec 的帮助下, 直接看 rspec 生成的文档就可以督促大家补全测试。
参考资料
[1] The RSpec Book